수업정리
Chapter 1. 인공지능 개요
- 인공지능
- 머신러닝
- 딥러닝
- 머신러닝 vs 딥러닝
Chapter 2. 머신러닝의 분류
- 지도학습
- 비지도학습
- 강화학습
Chapter 3. 지도학습 알고리즘
- 분류 (Classification)
- 회귀 (Regression)
- KNN
- SVM
- 의사결정나무
- 로지스틱 회귀
Chapter 4. 비지도학
- 군집(Clustering)
- K-Means
- DBSCAN
Chapter 5. 강화학습
- Q-Learning
- Deep Q Learning
Chapter 6. 핵심 개념
- 가중치 (Weight)
- 과적합 (Overfitting)
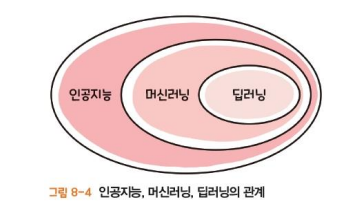
인공지능, 머신러닝, 딥러닝의 관계
1) 인공지능
- 인간이 가진 지적 능력을 컴퓨터를 통해 구현하는 기술
- 인공지능의 구분
- 강인공지능(Strong AI) : 인간의 능력을 초월한 성능을 가진 AI
- 약인공지능(Weak AI) : 특정 영역에서 도구로 사용하기 위해 설계된 AI
2) 머신러닝
- 컴퓨터를 인간처럼 학습 -> 컴퓨터 스스로가 새로운 규칙 발견
- 머신러닝은 기본적 알고리즘을 이용해 데이터를 분석하고, 분석을 통해 학습하며, 학습한 내용을 기반으로 판단 혹은 예측함
- 머신러닝이 스스로 학습하여 데이터를 처리하는 과정
- 빅데이터 입력
- 데이터 분석 -> 모델
- 모델을 이용하여 의사결정 및 예측 등을 수행

3) 딥러닝
- 인공신경망(ANN, Artificial Neural Network)
- 여러 뉴런이 서로 연결되어 있는 구조의 네트워크

- 딥러닝(Depp Learning)
- 여러 은닉충을 가진 인공신경망을사용하여 머신러닝 학습을 수행하는 기술
- 딥러닝의 '딥(Deep)'은 연속된 신경망 층(layer)을 깊게(deep) 쌓는다는 의미
- 신경망이 깊을 수록 성능 향상
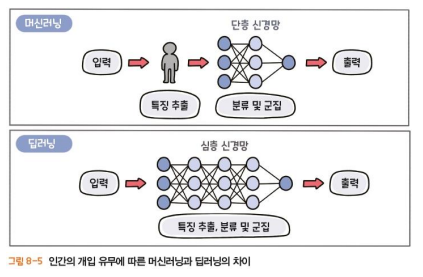
4) 머신러닝과 딥러닝의 차이점
- 인간의 개입 유무
- 머신러닝은 사람이 학습 데이터에 레이블(정답)을 알려주거나 데이터의 특징을 추출하는 등 어느정도 개입을 한다.
- 딥러닝은 인간의 개입 없이 컴퓨터가 스스로 학습한다.
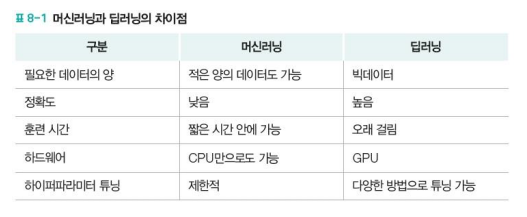
- 데이터 의존도(Data Dependencies)
- 딥러닝은 주어진 문제를 해결하기 위해 중요한 특징을 직접 추출
- 데이터의 양이 충분하지 않으면 정확한 특징을 추출할 수 없음
- 충분한 양의 데이터가 주어진다면 사람이 인지히지 못한 중요한 특징들까지 찾아낼 수 있을 정도로 좋은 성능 발휘
- 딥러닝은 주어진 문제를 해결하기 위해 중요한 특징을 직접 추출
- 심층 신경망의 사용 여부
- 딥러닝은 심층신경망을 이용하여 입력 데이터에서 특징을 추출하고 스스로 결과를 도출
- 심층신경망을 사용하는 것은 딥러닝만의 뚜렷한 특징
머신러닝의 분류
1) 머신러닝의 분류
- 지도학습 : 예측이나 분류를 위해 사용
- 비지도 학습 : 군집을 위해 사용
- 강화학습 : 환경에서 취하는행동에 대한 보상을 이용하여 학습 진행
2) 지도학습 (Supervised Learning)
- 문제와 답을 함께 학습함으로써 미지의 문제에 대한 올바른 답을 예측하는 학습
- 예측과 분류로 학습을 함
3) 비지도 학습 (Unsupervised Learning)
- 지도학습과 다르게 조력자의 도움없이 컴퓨터 스스로 학습하는 형태
- 컴퓨터가 훈련데이터를 이용하여 데이터들 간의 규칙성을 찾음
- x와 y의 관계를 파악했던 지도학습과는 달리, 비지도학습은 x 간의 관계를 스스로 파악
- 군집으로 학습함.
4) 강화학습(Reinforcement Learning)
- 자신이 한 행동에 대한 보상(Reward)을 받으며 학습하는 것
- 컴퓨터가 주어진 상태에 대해 최적의 행동을 선택하도록 학습하는 방법
- 강화학습을 이해하기 위해 알아야 할 개념들
- 에이전트(Agent) : 주어진 문제 상황에서 행동하는 주체
- 상태(State) : 현재 시점에서의 상황
- 행동(Action) : 플레이어가 취할 수 있는 선택지
- 보상(Reward) : 플레이어가 어떤 행동을 했을 때 따라오는 이득
- 환경(Environment) : 문제 그 자체를 의미
- 관찰(Observation) : 에이전트가 수집한(보고 듣는) 환경에 대한 정보
- 강화학습은 에이전트가 상태를 계속 주시하면서 보상이 높은 쪽으로 학습하게 됨
머신러닝 알고리즘의 유형
1) 머신러닝 알고리즘의 유형
- 지도학습 : 분류와 예측
- 비지도학습 : 군집
- 강화학습 : 큐러닝과 딥큐러닝
2) 분류(Classification)
- 레이블이 포함된 데이터를 학습하고 유사한 성질을 갖는데이터끼리 분류한 후, 새로 입력된 데이터가 어느 그룹에 속하는지를 찾아내는 기법
- 분류의 종류
- 이진분류(Binary Classification) : 데이터를 2개의그룹으로 분류
- 다중 분류(Multiclass Classification) : 데이터를 3개의 그룹 이상으로 분류

3) 분류에 해당하는 알고리즘
- k-최근접 이웃(KNN)
- 서포트 벡터 머신(SVM)
- 의사결정나무(Decision Tree)
- 로지스틱 회귀(Logistic Regression)
4) 분류 | K - 최근접 이웃 (KNN, K-Nearest Neighbors)
- 새로운 데이터가 들어왔을 때 기존 데이터의 그룹(K개의 그룹)중 어떤 그룹에 속하는지 분류하는 알고리즘

- KNN은 학습 데이터 내에 존재하는 노이즈의 영향을 크게 받지 않으며, 학습 데이터 수가 많을 때 꽤 효과적인 알고리즘
- 하지만 어떤 하이퍼파라미터가 분석에 적합한지는 불분명해, 데이터 각각의 특성에 맞게 연구자가 임의로 선정해야 한다는 단점이 있음
노이즈(Noise) - 데이터에 무작위 오류(Random Error)또는 분산(Variance)이 존재하는것임.
5) 분류 | 서포터 벡터 머신 (SVM, Support Vector Machine)
- 주어진 데이터가 어느 그룹에 속하는지 분류하는 모델
- 두 분류 사이의 여백을 의미하는 마진을 최대화하는 방향으로 데이터를 분류
- SVM은 마진을 극대화하는 선을 찾아 분류하므로 마진이 크면 클수록 새로운 데이터가 들어오더라도 잘 분류할 가능성이 높아짐
- SVM은 사용 방법이 쉽고 예측 정확도가 높다는 장점
- 하지만 모델 구축에 시간이 오래 걸리고 결과에 대한 설명력이 떨어지는 단점

6) 분류 | 의사결정나무(Decision Tree)
- 의사결정 규칙을 나무 형태로 분류하는 분석 방법
- 분석과정이 직관적이고 이해하기 쉬움
- 인공신경망의 경우 분석 결과에 대한 설명이 어려운 블랙박스 모델인 반면, 의사결정 나무는 분석과정을 눈으로도 관측할 수 있음
- 그래서 결과에 대한 명확한 설명이 필요할 때 많이 사용함
7) 분류 | 로지스틱 회귀(Logistic Regression)
- 데이터가 어떤 범주에 속할 확률을 0~1 사이의 값으로 정해놓고, 그 확률에 따라 가능성이 더 높은 범주에 속하는 것으로 분류해 주는 지도학습 알고리즘
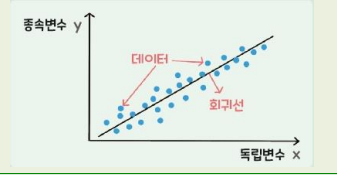
- 회귀(Regression)
- 연속형 변수들에 대해 변수 간 관계를 추정하는 분석 방법이며, 선형 회귀는 독립변수와 종속변수가 직선의 형태를 취하는 관계
이분변수, 이산형변수, 연속형 변수
- 이분변수
- 두 개의 값만을 가질 수 있는 변수

- 로지스틱 회귀는 선형 회귀와는 다르게 종속변수가 범주형 데이터
- 즉, 입력 데이터가 주어졌을 때 해당 데이터의 결과가 0과 1 사이의 값을 가짐
- 결괏값이 정해진 범주 내에서 나오므로 확률적인 의미에서 사건 발생 가능성을 예측하는 데 사용할 수 있음
- 선형 회귀는 종속변수로 올 수 있는 값에 대한 제약이 없는 반면, 로지스틱 회귀의 종속변수는 값이 제한적이라는 것에 주목해야 함
8) 분류 | 회귀
- 회귀는 연속형 변수를 예측하는데 사용됨, 즉 연속적인 숫자나 실수를 예측함( 예 : 주식, 부동산 가격 예측)
- 종속변수와 독립변수 간의 관계를 살펴 볼 때 유용하게 사용
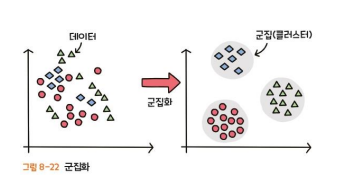
군집화
- 군집 (Cluster)
- 비슷한 특징을 가진 데이터들의 집단
- 군집화 (Clustering)
- 데이터가 주어졌을 때, 그 데이터들을 유사한 정도에 따라 군집으로 분류하는 것
1 ) K-Means Clustering(k - 평균 군집화)
- 'k'는 주어진 데이터로부터 묶여질 그룹(군집의 수)
- 'Means'는각 군집의 중심과 데이터들의 평균거리를 의미
- 클러스터의 중심을 (Centroids)이라고 함

2 ) 밀도기반 클러스터링(DMSCAN)
- 밀도를 기반으로 군집화하는 군집 알고리즘
- 밀도기반 클러스터링은 데이터들의 분포
- 밀도기반 클러스터링을 이해하기 위한 관련 용어
» ε(Epsilon, 거리) : 하나의 점으로부터의 반경
» minPth(Minimum Points, 최소점) : 군집을 이루기 위한 최소한의 데이터 수
3) 밀도기반 클러스터링의 진행 과정(ε=5cm, minPth=4라고 가정)
1단계 : 한 점을 중심으로 반경 5cm거리에 4개의 데이터가 있는지
(minPth=4를 만족하는지) 확인
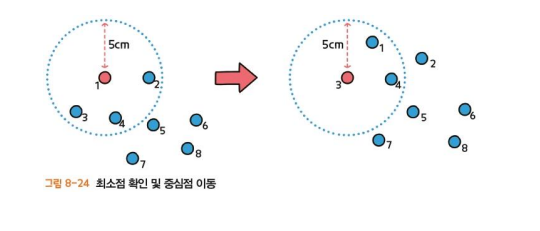
2단계 : 이동한 중심점 3을 기준으로 1단계를 반복하는데, 3을 기준으로 반 5cm 이내에 데이터가 4개 초과 있는지 확인하면, 역시 데이터의 수가 4보다 작으므로 이번에는 중심점을 4로 지정함
3단계 : 4를 중심점으로 했을 때 데이터의 수가 4를 초과하므로 군집이 생성

K-평균 군집화와 달리 밀도기반 클러스터링은 클러스터 수를 지정할 필요가 없음
– 더 중요한 것은 밀도기반 클러스터링은 K-평균 군집화가 찾을 수 없는 임의의 모양들을 가질 수 있다는 점임
– 예를 들어, 밀도기반 클러스터링은 [그림 8-26]의 첫 번째 그림과 같이 다른 군집으로 둘러 싸인 상태에서 또 다른 군집을 가질 수 있음

강화학습 기술
1) 큐러닝(Q-Learning)
특정 상태에서 어떤 결정을 내려야 미래 보상이 극대화 될 것인지에 대한 정책을 지속적으로 업데이트
모델없이학습하는 대표적인 강화학습 알고리즘
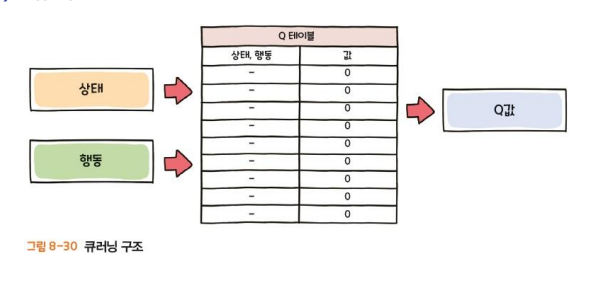
보상값을 업데이트 해 나가면서 강화학습을 진행함
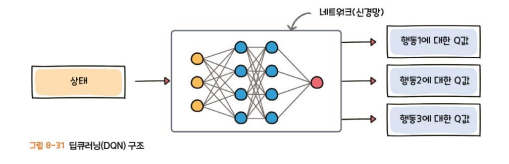
2) 딥큐러닝(Depp Q Learning)
큐러닝 + 신경망을 결합한 알고리즘
큐러닝에서는 보상값을업데이트 하기위해 테이블을 이용했다면, DQN에서는 네트워크(신경망)을 이용
Q값은 전략에 따라 행동했을 때 미래에 보상들에 대한 기댓값의 총합이다.
결국 Q러닝과 DQN모두 Q값이 높은 쪽으로 행동하는 것을목표로한다.
가중치 (Weight)
- 입력 신호가 출력에 미치는 중요도를 조절하는 매개변수
과적합(Overfitting)
- 훈련 데이터를너무 과하게 학습하여 실제 데이터를 분석할 때는 성능이 좋지 못한 것을 의미
- 문제의 복잡도에 비해 데이터가 현저히부족한 경우, 즉 문제 된 전체 공간을 학습데이터가 아우르지 못하고 일부 경우에만 집중했을 경우 발생됨

'Programing' 카테고리의 다른 글
| Python - Class (0) | 2026.04.17 |
|---|---|
| Python - List (0) | 2026.04.14 |
| 빅데이터 (0) | 2026.04.09 |
| 인공지능을 실현하기 위한 기술 (3) | 2026.04.09 |
| [speakLogs] #2 OpenAPI-Key 발급받기 (0) | 2026.03.30 |



